
Travers Rhodes
Software Engineer (Robotics)
Boston area
I am a Senior Software Engineer at Berkshire Grey, a warehouse robotics company.
My work has included helping bring the CarouselAI item picking robot to production readiness,
updating the Robotic Pick Cell code to ROS 2 and Python 3,
reducing error detection time on the SpectrumGripper™ proprietary gripper technology,
and helping maintain the core codebase used in robotic warehouses to pick millions of items in a day.
The views expressed on this website are my own.
I received my PhD in computer science from Cornell University, advised by Daniel Lee. My research focused on manipulation, assistive robotics, and machine learning. My primary research question was “How can we make learned latent spaces more interpretable and more useful for robotics?” I investigated how regularization and architectural choices affect the performance of Varational Auto-Encoders in modeling demonstrated trajectories.
I received my masters degree in robotics from Carnegie Mellon University in 2019, working in Manuela Veloso's lab.
At CMU, I was involved in two main projects related to the robotic manipulation of food. The Feedbot project, a collaboration with Instituto Superior Tecnico in Lisbon, Portugal, involved assistive eating. The other, a collaboration with Sony Corporation, involved robotic food preparation. For the assistive eating project, we were trying to improve the robustness of spoon-feeding robots for people living with upper-extremity disabilities by incorporating better visual feedback on the robot. For that project, I 3D-printed and wrote custom firmware for a Niryo One robot arm, and designed and incorporated an end-effector that could hold a spoon and a camera. For the food-preparation project, I worked to increase the efficiency of a food-plating robot. More details on the food-preparation project can be found in this IEEE Spectrum article.
I earned my undergraduate degree at Harvard, where I studied physics and mathematics. Between my undergraduate and graduate studies, I worked as a senior software engineer at Applied Predictive Technologies (now part of Mastercard Data and Services), writing cloud-based data analytics software.
|
|
Doctoral Thesis
For robots to perform intricate manipulation skills, like picking up a slippery banana slice with a fork, it is often useful to have a human demonstrate how to perform that skill for the robot. Humans can perform the desired motion multiple times in front of the robot, and the robot can record the demonstrated trajectories and build a model of the demonstrations. If the robot can learn a good model of the different ways to perform the desired motion, the human and the robot can then work together to pick a trajectory for the robot to perform to solve the task. This dissertation investigates the machine learning component of that example: "How can a robot learn a good model of demonstrated trajectories?" We present multiple advances in the ability of robots to model demonstrated trajectories using latent variable models. These approaches include better model regularization to take advantage of the small size of datasets of human demonstrations, better architectural choices to separate the timing and spatial variations of the demonstrated trajectories, and an investigation into how to disentangle the meaning of the variables in the latent variable model. Theoretical justifications for the contributions are presented alongside empirical evaluations performed on a physical robot arm.
|
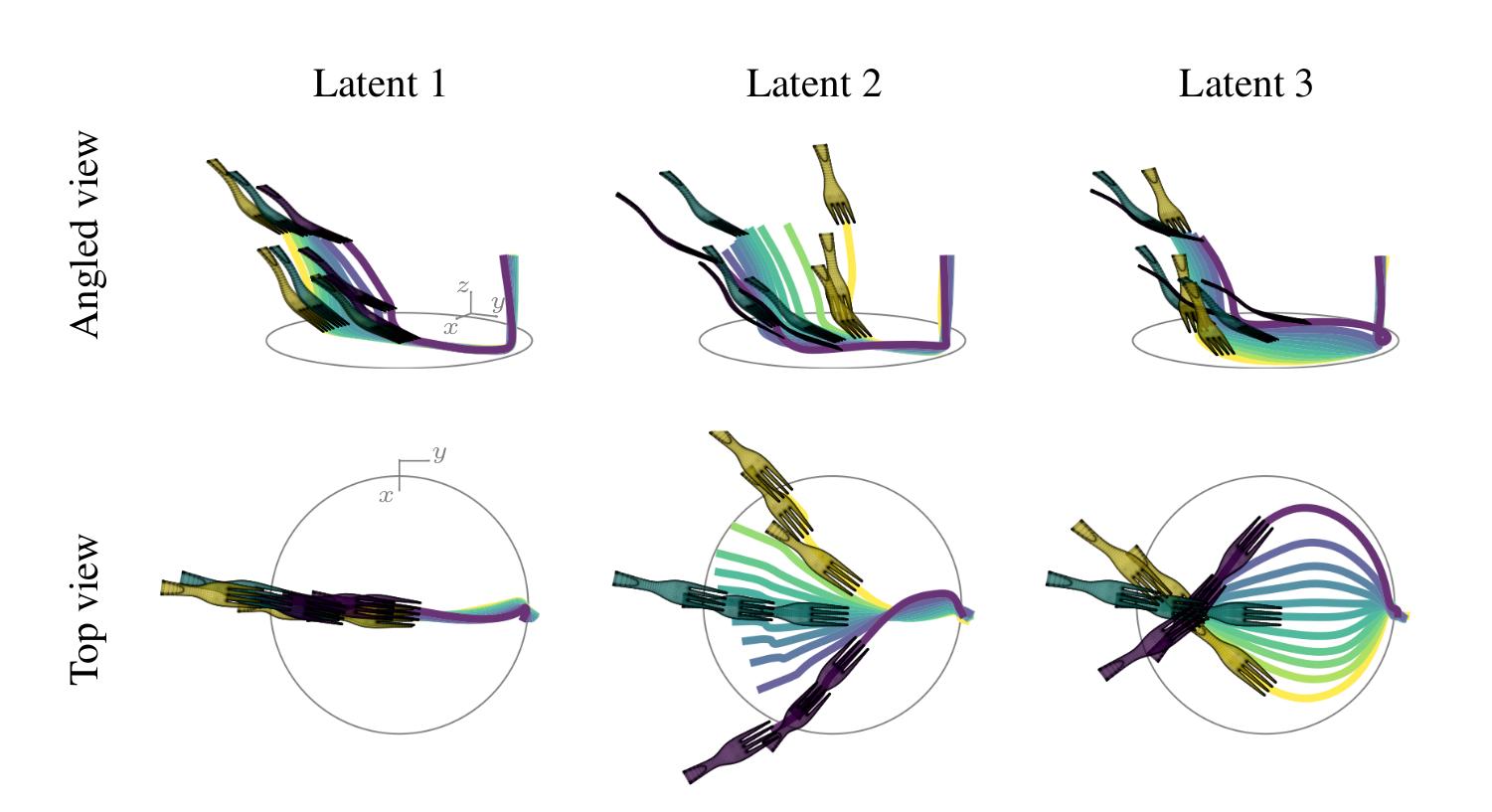  |
AI4TS AI for Time Series Analysis: Theory, Algorithms, and Applications Workshop at the 2024 International Joint Conferences on Artificial Intelligence (IJCAI) Best Poster Award
Human demonstrations of trajectories are an important source of training data for many machine learning problems. However, the difficulty of collecting human demonstration data for complex tasks makes learning efficient representations of those trajectories challenging. For many problems, such as for dexterous manipulation, the exact timings of the trajectories should be factored from their spatial path characteristics. In this work, we propose TimewarpVAE, a fully differentiable manifold-learning algorithm that incorporates Dynamic Time Warping (DTW) to simultaneously learn both timing variations and latent factors of spatial variation. We show how the TimewarpVAE algorithm learns appropriate time alignments and meaningful representations of spatial variations in handwriting and fork manipulation datasets. Our results have lower spatial reconstruction test error than baseline approaches and the learned low-dimensional representations can be used to efficiently generate semantically meaningful novel trajectories. We demonstrate the utility of our algorithm to generate novel high-speed trajectories for a robotic arm.
|
|
|
In Proceedings of IROS'22, the IEEE/RSJ International Conference on Intelligent Robots and Systems, Kyoto, Tokyo. 2022.
Learning intricate manipulation skills from human demonstrations requires good sample efficiency. We introduce a novel learning algorithm, the Curvature-regularized
Variational Auto-Encoder (CurvVAE), to achieve this goal. The CurvVAE is able to model the natural variations in human-
demonstrated trajectory data without overfitting. It does so by
regularizing the curvature of the learned manifold. To showcase
our algorithm, our robot learns an interpretable model of the
variation in how humans acquire soft, slippery banana slices
with a fork. We evaluate our learned trajectories on a physical
robot system, resulting in banana slice acquisition performance
better than current state-of-the-art.
|
|
In Proceedings of Advances in Neural Information Processing Systems 34 (NeurIPS 2021)
There have been many recent advances in representation learning; however, unsupervised representation learning can still struggle with model identification issues related to rotations of the latent space. Variational Auto-Encoders (VAEs) and their extensions such as β-VAEs have been shown to improve local alignment of latent variables with PCA directions, which can help to improve model disentanglement under some conditions. Borrowing inspiration from Independent Component Analysis (ICA) and sparse coding, we propose applying an L1 loss to the VAE's generative Jacobian during training to encourage local latent variable alignment with independent factors of variation in images of multiple objects or images with multiple parts. We demonstrate our results on a variety of datasets, giving qualitative and quantitative results using information theoretic and modularity measures that show our added L1 cost encourages local axis alignment of the latent representation with individual factors of variation.
|
|

|
Masters Thesis
Food manipulation offers an interesting frontier for robotics research because of the direct application of this research to real-world problems and the challenges involved in robust manipulation of deformable food items. In this work, we focus on the challenges associated with robots manipulating food for assistive feeding and meal preparation. This work focuses on how we can teach robots visual perception of the objects to manipulate, create error recovery and feedback systems, and improve on kinesthetic teaching of manipulation trajectories. This work includes several complete implementations of food manipulation robots for feeding and food plating on several robot platforms: a SoftBank Robotics Pepper, a Kinova MICO, a Niryo One, and a UR5.
|
|
|
AIxFood Workshop at the 2019 International Joint Conferences on Artificial Intelligence (IJCAI)
Robots with manipulation skills acquired through trajectory cloning, a type of learning from demonstration, are able to accomplish complicated manipulation tasks. However, if the skill is demonstrated on one arm and applied to a different arm with different kinematics, the cloned trajectory may not be well matched to the new robot's kinematics and may not even be feasible on the new robot. Additionally, even if the new skill is demonstrated and applied on the same robot, the demonstrated trajectory might be feasible in the training configuration, but may not be feasible under desired translations of the trajectory, since the translated trajectory might go outside the robot's workspace. For some tasks like picking up a tomato slice, rotations of the trained trajectory would be successful in accomplishing the task. In this paper, we address how a robotic system can use knowledge about its own kinematic structure to rotate trained trajectories so that the new trajectories are feasible and lower cost on the robotic system, while still mimicking the trajectories defined for the robot by the human demonstrator.
|
|
|
In Proceedings of IROS'18, the IEEE/RSJ International Conference on Intelligent Robots and Systems, Madrid, Spain. 2018.
Kinesthetic learning is a type of learning from demonstration in which the teacher manually moves the robot through the demonstrated trajectory. It shows great promise in the area of assistive robotics since it enables a caretaker who is not an expert in computer programming to communicate a novel task to an assistive robot. However, the trajectory the caretaker demonstrates to solve the task may be a high-cost trajectory for the robot. The demonstrated trajectory could be high-cost because the teacher does not know what trajectories are easy or hard for the robot to perform, which would be due to a limitation of the teacher's knowledge, or because the teacher has difficulty moving all the robotic joints precisely along the desired trajectories, which would be due to a limitation of the teacher's coordination. We propose the Parameterized Similar Path Search (PSPS) algorithm to extend kinesthetic learning so that a robot can improve the learned trajectory over a known cost function. This algorithm is based on active learning from the robot through collaboration between the robot's knowledge of the cost function and the caretaker's knowledge of the constraints of the assigned task.
|
|
|
The IEEE European Conference on Computer Vision (ECCV) Workshops. 2018.
Researchers have over time developed robotic feeding assistants to help at meals so that people with disabilities can live more autonomous lives. Current commercial feeding assistant robots acquire food without feedback on acquisition success and move to a preprogrammed location to deliver the food. In this work, we evaluate how vision can be used to improve both food acquisition and delivery. We show that using visual feedback on whether food was captured increases food acquisition efficiency. We also show how Discriminative Optimization (DO) can be used in tracking so that the food can be effectively brought all the way to the user's mouth, rather than to a preprogrammed feeding location.
|
|
|
Proceedings of The 2nd Conference on Robot Learning, PMLR 87:529-550, 2018.
Granular materials produce audio-frequency mechanical vibrations in air and structures when manipulated. These vibrations correlate with both the nature of the events and the intrinsic properties of the materials producing them. We therefore propose learning to use audio-frequency vibrations from contact events to estimate the flow and amount of granular materials during scooping and pouring tasks. We evaluated multiple deep and shallow learning frameworks on a dataset of 13,750 shaking and pouring samples across five different granular materials. Our results indicate that audio is an informative sensor modality for accurately estimating flow and amounts, with a mean RMSE of 2.8g across the five materials for pouring. We also demonstrate how the learned networks can be used to pour a desired amount of material.
|
 |
In Proceedings of the 17th International Conference on Autonomous Agents and MultiAgent Systems (pp. 883-891). International Foundation for Autonomous Agents and Multiagent Systems. July, 2018.
Pepper is a humanoid robot, specifically designed for social interaction, that has been deployed in a variety of public environments. A programmable version of Pepper is also available, enabling our focused research on perception and behavior robustness and capabilities of an interactive social robot. We address Pepper perception by integrating state-of-the-art vision and speech recognition systems and experimentally analyzing their effectiveness. As we recognize limitations of the individual perceptual modalities, we introduce a multi-modality approach to increase the robustness of human social interaction with the robot. We combine vision, gesture, speech, and input from an onboard tablet, a remote mobile phone, and external microphones. Our approach includes the proactive seeking of input from a different modality, adding robustness to the failures of the separate components. We also introduce a learning algorithm to improve communication capabilities over time, updating speech recognition through social interactions. Finally, we realize the rich robot body-sensory data and introduce both a nearest-neighbor and a deep learning approach to enable Pepper to classify and speak up a variety of its own body motions. We view the contributions of our work to be relevant both to Pepper specifically and to other general social robot.
|
I grew up in Hanover, NH, and I enjoy hiking, singing, rowing, and travel.
I am married to C. Taylor Poor, a public defender, whom I met in 2009.

You can reach me at tsr42 [at] cornell [dot] edu.
You can also find more about me at my Google Scholar Profile and on LinkedIn.